Changing Search Engines
I’ve become increasingly concerned about Google’s storing of search data. I use various cookie blockers, page rewriters, and other tools to limit the information Google gets about me. Nonetheless I still have a static IP address that’s only shared with a few other people; and if any company has the skill and talent to aggregate search requests to build profiles of people and invade their privacy, it’s Google. Consequently, I’m switching over Firefox to use a different search engine. I thought I’d start by trying generic.a9.com which promises not to track me. (The regular www.a9.com does track users.) Here’s how:
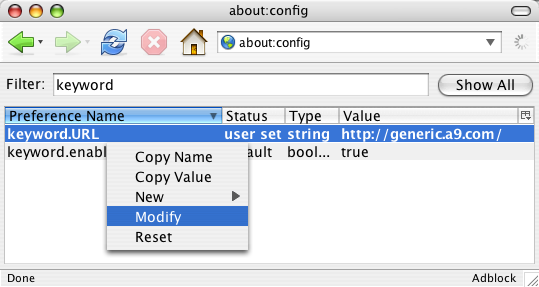
- Type about:config in the location bar
- Type “keyword” in the Filter field
- Right-click keyword.URL and select “Modify” from the pop-up menu
- Change the value to
http://generic.a9.com/ - Click OK.
- Close the window
That’s it. You’re now using A9’s generic service. Update: It seems A9 violates the URL spec somehow by treating http://generic.a9.com/query%20term differently from http://generic.a9.com/query+term. it works with the former but not the latter, which is what Firefox sends for multiword queries. That rules it out. I’ll have to try a different one.
Other search engines can be configured similarly. Just the URL changes. In most cases, however, you’ll need more than the URL for the home page. For instance, the URL for IXQuick is http://us.ixquick.com/do/metasearch.pl?query=
The big question is how the other search services compare to Google. So far, A9 does not seem to be doing so well. It used to be better, but it used to be powered by Google. Now it’s powered by Microsoft’s Live.com, a distinctly inferior search engine. IxQuick is a meta search engine that accumulates results from several search engines. The theory is that a URL that shows up in several search engines is more likely to be relevant than one that only shows up in one or two. The reality is that the bad results from non-Google engines end up polluting the good results from Google. Plus it looks uglier than Google. Scroogle is nothing more than an anonymizing, ad-free front-end to Google. That makes it one of the better alternatives out there, except that it violates the web architecture by using POST for safe operations instead of GET. Consequently, it can’t be used from within Firefox’s search bar and location bars.
Still, even if the other search engines are a little slower, uglier, and less effective than Google, I’m just not comfortable with Google storing all my search requests tied to my IP address for an undefined but lengthy period of time, so I’m going to try living with the others for a few weeks. I’ll let you know how it goes.

August 30th, 2006 at 8:37 AM
Using POST for safe operations is not a violation of REST; it’s using GET for unsafe ones that is Evil and Rude. Conceptually, POST says “Apply this entity-body I’m sending you to the existing resource named by this URI and send back the representation (and the URI, if you have one) of a novel resource.” That’s an apt description of what search engines do, so using GET is just a matter of convenience — and very convenient too, don’t get me wrong. But using POST is perfectly acceptable.
August 30th, 2006 at 9:38 AM
Technically using POST for a safe operation may not violate REST principles, but the Web architecture is a little more specific than just REST; and I do think that using POST for a simple query indeed violates the Web architecture. In particular, I cite the W3C TAG finding on “URIs, Addressability, and the use of HTTP GET and POST” which states unequivocally and up front that, “HTTP GET promotes URI addressability so, designers should adopt it for safe operations such as simple queries.” The finding goes into great detail to explain exactly why this is so.
August 31st, 2006 at 11:27 AM
Have you considered this alternative? TrackMeNot is a Firefox plugin. The basic premise is that your thoughtful searches will fall into the noise of TMN’s randomly generated queries (i.e. “Perls uploading chomping ganges”).
As far as the practice of collecting search info, I’m somewhat divided so long as an option of privacy is available. Individual privacy is critical to a free society, yet being able to gather broad societal trends is a facinating tool to have .
August 31st, 2006 at 1:41 PM
One warning about using TMN…seems that Google interprets too many searches as the actions of spyware and will lock you out until you enter a human readable GIF, so you’ll probably have to decrease the frequency of the generated queries.
September 5th, 2006 at 9:22 AM
Have you considered using an anonimity service like TOR for your search queries? It might be a bit slower, but if you only use it for google it should work out ok..
September 6th, 2006 at 8:25 AM
I still don’t get it why an anonymous proxy or anonymity service won’t cut it for you. I suggested JAP others TOR. JAP is an easy to use local HTTP proxy that connects to a (MIX network of) proxies over HTTPS. It can go through the TOR netrwork as well. Anyway, at least you can keep posting about your adventures :).
September 25th, 2006 at 9:42 AM
Proxies don’t cut it because they’re:
1. Unusably slow
2. All-or-nothing
I only want to anonymize the searching, not everything I do.